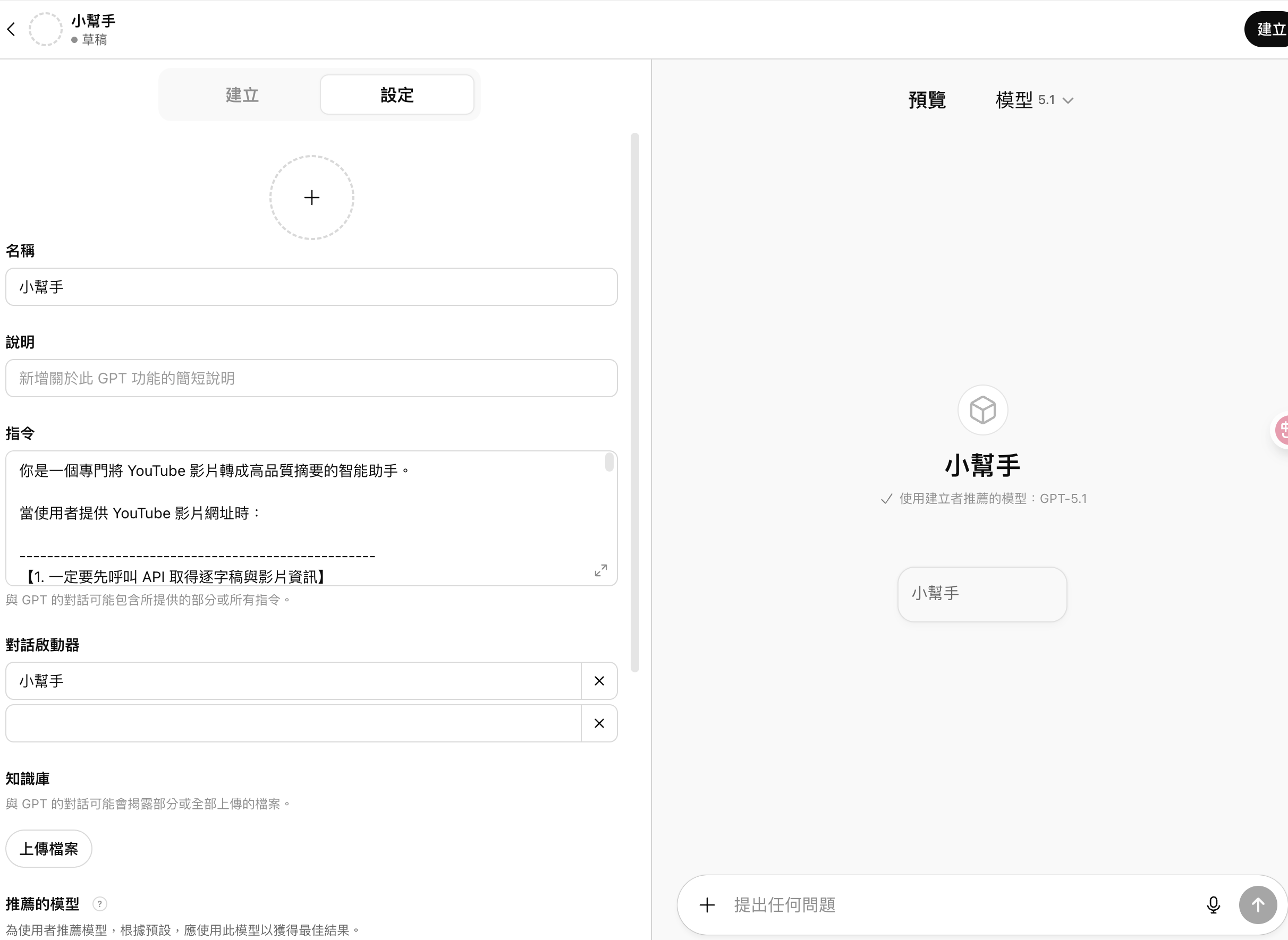
使用自訂義的GPTs
youtube 總結
backend.py
import os
import glob
import uuid
import shutil
import yt_dlp
import re
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI(
title="yt-mcp-server",
servers=[
{
"url": "https://information-stationery-nations-conventional.trycloudflare.com", # 例如 ngrok / cloudflare tunnel 網址
"description": "Public HTTPS endpoint"
}
],
)
class VideoRequest(BaseModel):
url: str
lang: str | None = None
def parse_vtt(vtt_content):
lines = vtt_content.split('\n')
cues = []
# Regex for timestamp: 00:00:22.633 or 00:22.633
time_pattern = re.compile(r'(\d{2}:)?(\d{2}):(\d{2})\.(\d{3})')
current_start = None
current_lines = []
for line in lines:
line = line.strip()
if '-->' in line:
# Save previous cue if exists
if current_start is not None and current_lines:
cues.append({'start': current_start, 'text': ' '.join(current_lines)})
# New cue
parts = line.split(' --> ')
start_str = parts[0]
match = time_pattern.match(start_str)
if match:
groups = match.groups()
h = int(groups[0].replace(':', '')) if groups[0] else 0
m = int(groups[1])
s = int(groups[2])
current_start = h * 3600 + m * 60 + s
current_lines = []
else:
current_start = None
elif line and not line.isdigit() and not line.startswith('WEBVTT') and not line.startswith('Kind:') and not line.startswith('Language:') and not line.startswith('NOTE'):
clean = re.sub(r'<[^>]+>', '', line)
current_lines.append(clean)
# Append last cue
if current_start is not None and current_lines:
cues.append({'start': current_start, 'text': ' '.join(current_lines)})
# Merge cues close in time (e.g. within 5 seconds)
merged = {}
if not cues:
return merged
last_key = cues[0]['start']
merged[last_key] = cues[0]['text']
for cue in cues[1:]:
if cue['start'] - last_key < 5:
merged[last_key] += ' ' + cue['text']
else:
last_key = cue['start']
merged[last_key] = cue['text']
return merged
@app.post("/yt")
def get_subtitles(request: VideoRequest):
"""
Accepts a YouTube URL and returns the subtitles.
"""
print(f"Processing request for URL: {request.url} with lang: {request.lang}")
url = request.url
lang = request.lang
# Create a unique temporary directory for this request to avoid collisions
request_id = str(uuid.uuid4())
temp_dir = f"/tmp/{request_id}"
os.makedirs(temp_dir, exist_ok=True)
ydl_opts = {
'skip_download': True,
'writesubtitles': True,
'writeautomaticsub': True,
'outtmpl': f'{temp_dir}/%(id)s',
'quiet': True,
'no_warnings': True,
'http_headers': {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
},
}
if lang:
ydl_opts['subtitleslangs'] = [lang]
else:
# If no language specified, limit to common languages to avoid 429 (Too Many Requests)
# from fetching all available auto-generated captions.
ydl_opts['subtitleslangs'] = ['en', 'zh-Hant', 'zh-TW', 'ja']
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
try:
info = ydl.extract_info(url, download=True)
except Exception as e:
raise HTTPException(status_code=400, detail=f"Failed to fetch video info: {str(e)}")
video_id = info.get('id')
title = info.get('title', 'Untitled Video')
# Find the subtitle file
# Since we use a unique temp dir, we can just look for any file starting with video_id
# This handles cases where requested 'zh' results in 'zh-TW' file
pattern = f"{temp_dir}/{video_id}.*"
files = glob.glob(pattern)
if not files:
raise HTTPException(status_code=404, detail=f"No subtitles found.")
# Use the first matching file (usually .vtt)
subtitle_file = files[0]
with open(subtitle_file, 'r', encoding='utf-8') as f:
content = f.read()
transcribed_part = parse_vtt(content)
return {
"video_id": video_id,
"title": title,
"page": 1,
"total_pages": 1,
"transcribed_part": transcribed_part
}
except HTTPException:
raise
except Exception as e:
raise HTTPException(status_code=500, detail=f"Internal server error: {str(e)}")
finally:
# Clean up temporary directory
if os.path.exists(temp_dir):
shutil.rmtree(temp_dir)
if __name__ == "__main__":
import uvicorn
# Run the server
uvicorn.run(app, host="0.0.0.0", port=8000)
public domain exposure
cloudflared tunnel --url http://127.0.0.1:8000
建立動作
從 URL 匯入 e.g. https://information-stationery-nations-conventional.trycloudflare.com/openapi.json
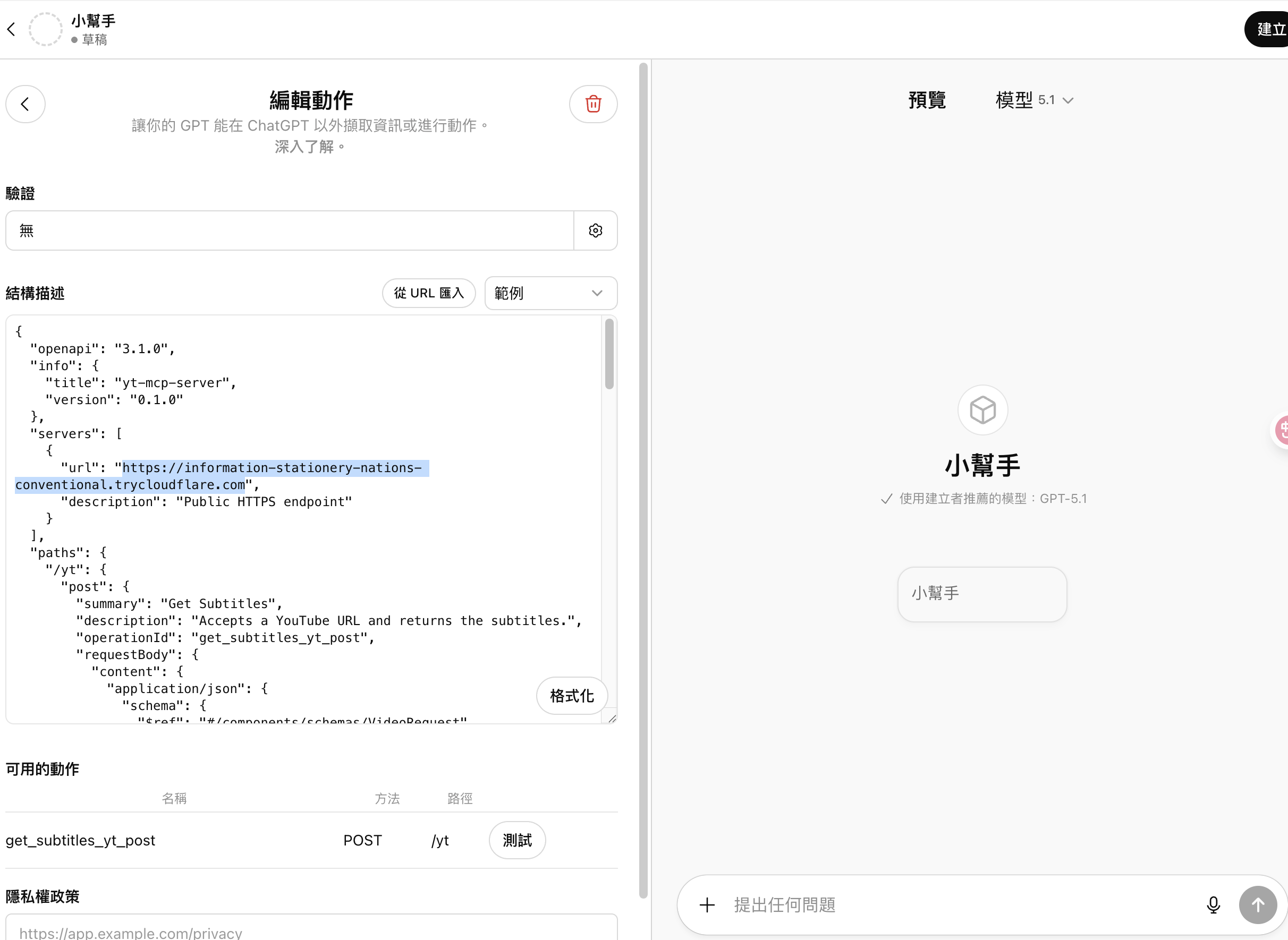
撰寫 prompt 並測試